Kardiovaskuläre Mortalität: Machine Learning übertrifft etablierte Risikovorhersageansätze
Heterogene Datensätze eignen sich optimal für das Training artifizieller neuronaler Netzwerke. Anhand dieser können prognostischen Fähigkeiten trainiert werden, um Kardiologen in ihrem klinischen Alltag zu unterstützen.
Das sollten Sie zum Einsatz der KI in der Kardiologie wissen:
- Künstliche Intelligenz unterstützt Kardiologen von der Terminvergabe bis hin zur prognostischen Patientenstratifizierung in allen Bereichen.
- Machine Learning ist ein Computeralgorithmus, der durch die Identifizierung und Analyse von Mustern Vorhersagen für den weiteren Krankheitsverlauf treffen kann.
- Patienten mit niedrigem und mittlerem kardiovaskulären Risiko wurden mittels Machine Learning basierten Risikoscore hinsichtlich dem Mortalitätsrisiko besser eingeteilt als mit den klassischen Risikoscores.
Wie lassen sich Künstliche Intelligenz, Machine Learning und Deep Learning definieren?
"Die Artificial Intelligence (Künstliche Intelligenz) ist letztendlich alles, was einem Computer erlaubt, Aufgaben zu übernehmen, die klassischerweise eigentlich Aufgaben menschlicher Intelligenz gewesen sind. Das Machine Learning ist eine Subdisziplin der Künstlichen Intelligenz. Beim Deep Learning werden artifizielle "neural networks" (neuronale Netzwerke) genutzt um Vorhersagen zu machen anhand von z. B. MRT-Datensätzen."
Andreas Scheuer zur Definition der Künstlichen Intelligenz, des Machine Learning und des Deep Learning.1
Künstliche Intelligenz optimiert klinischen Alltag der Kardiologie
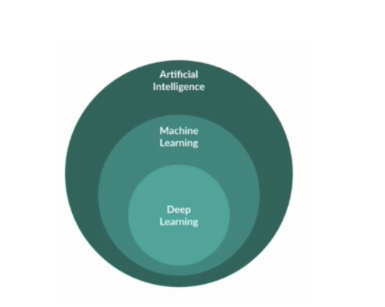
Abbildung 1: Unter Künstlicher Intelligenz werden auch Subdisziplinen, wie das Machine Learning zusammengefasst. Im Zentrum des Ganzen steht das Deep Learning, welches durch artifizielle neuronale Netzwerke eigenständig lernen und Aufgaben bewältigen kann. Bildquelle1
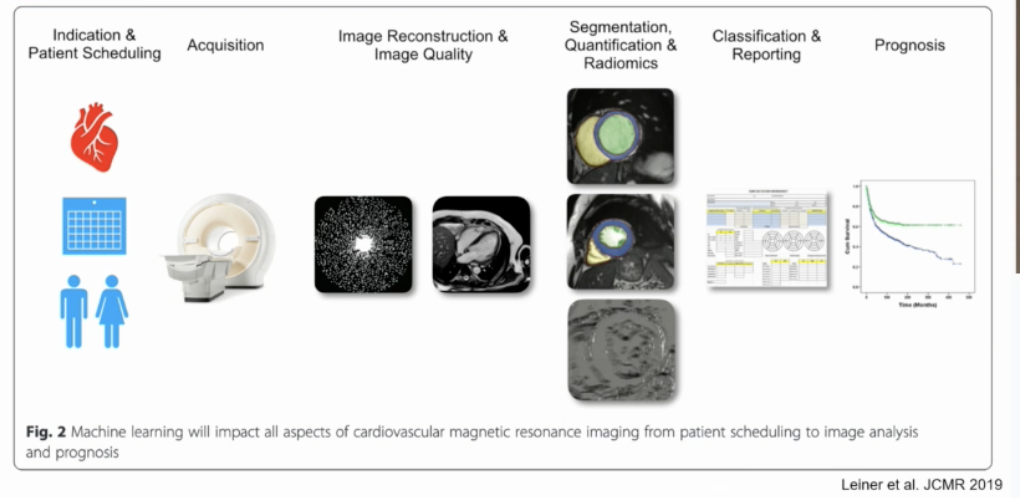
Abbildung 2: Die Künstliche Intelligenz bietet vielzählige Möglichkeiten der Prozessoptimerung im klinischen Alltag des Kardiologen. Das Machine Learning kann einfache Aufgaben, wie die Terminvergabe bis hin zu komplexen Bildanalysen und Prognosen des individuellen Krankheitsverlaufs übernehmen.
Die Künstliche Intelligenz wird im klinischen Alltag des Kardiologen bald nicht mehr wegzudenken sein
Der Einsatz der Künstlichen Intelligenz führt zu einer Verbesserung und Beschleunigung der einzelnen Vorgänge in der Kardiologie. Die vorliegende Grafik (Abbildung 2) zeigt auf, in welchen Bereichen die Künstliche Intelligenz bereits eine Rolle spielt:
- Indikationsstellung
- Terminvergabe
- Akquisition der Bilder
- Bildrekonstruktion und Artefaktreduktion
- Bildauswertung
- Klassifikation der Erkrankungen
- Reporting-System
- prognostische Stratifizierung der Patienten
Big Data des KOICA-Registers als Trainingsmodell für das Machine Learning
In einer wissenschaftlichen Studie wurden die Datensätze aus einer großen Kohorte des KOICA-Registers (Korea Initiative Coronary Calcification Registry) aus Südkorea für das Training und die Validierung eines Machine Learning basierten kardiovaskulären Vorhersagemodells herangezogen. 70% der Patienten waren in dem Training-Set und 30% in dem Testing-Set des Machine Learning Algorithmus. Das entwickelte Machine Learning Modell wurde in einer separaten Kohorte von insgesamt 4.915 Patienten validiert.1,2
Machine Learning versus etablierte kardiovaskuläre Risikoscores: Wer macht das Rennen?
Unter Verwendung der Datensätze von insgesamt 86.155 Patienten des KOICA-Registers wurden die prognostischen Fähigkeit eines Machine Learning basierten Vorhersagealgorithmus untersucht. Hierzu wurden Routineuntersuchungsdaten zur Vorhersage der Gesamtmortalität verwendet und mit etablierten Risikovorhersageansätzen verglichen. Die 70 Parameter umfassten u. a. 35 klinische, 32 Labor- und 3 Calcium-Score- (CACS= coronary artery calcium score) Parameter. Mittels Machine Learning wurden prädiktive Aussagen hinsichtlich des klinischen Outcomes anhand der 70 unterschiedlichen Parameter der jeweiligen Patientinnen und Patienten gemacht. Klassische Risikoscores (Framingham Risikoscore und ASCVD- (arteriosclerotic cardiovascular disease) Risikoscore) in Verbindung mit dem Calcium-Scoring (CACS-Score) wurden in Verhältnis zu einem reinem Machine Learning basierten Risikoscore ohne User-Interaktion gesetzt. Patienten mit niedrigem und mittlerem kardiovaskulären Risiko wurden mittels Machine Learning basierten Risikoscore besser eingeteilt als mit den klassischen Risikoscores. Für diese Patientengruppe konnte der Computeralgorithmus das Mortalitätsrisiko mit einer größeren Sicherheit als die etablierten Risikovorhersageansätze bestimmen.1,2
Fazit für die Praxis
- Machine Learning basierte Vorhersagemodelle übertreffen die klassischen Risikoscores hinsichtlich Vorhersage der Gesamtmortalität bei Patienten mit niedrigem und mittlerem kardiovaskulären Risiko.
- In der asymptomatischen Bevölkerung ist eine Verbesserung der Reklassifizierung gegenüber etablierten konventionellen Risikovorhersageansätzen im Rahmen der kardiovaskulären Gesundheitsuntersuchung durch ML möglich.1,2